-
[dacon] 와인품질 EDA 및 1차 모델 개발ML&DL 2021. 6. 14. 15:35
https://dacon.io/competitions/open/235610/overview/description
[화학] 와인 품질 분류
출처 : DACON - Data Science Competition
dacon.io
위 데이터를 활용했고, 기존에 작성했던 EDA글을 토대로 진행했다.
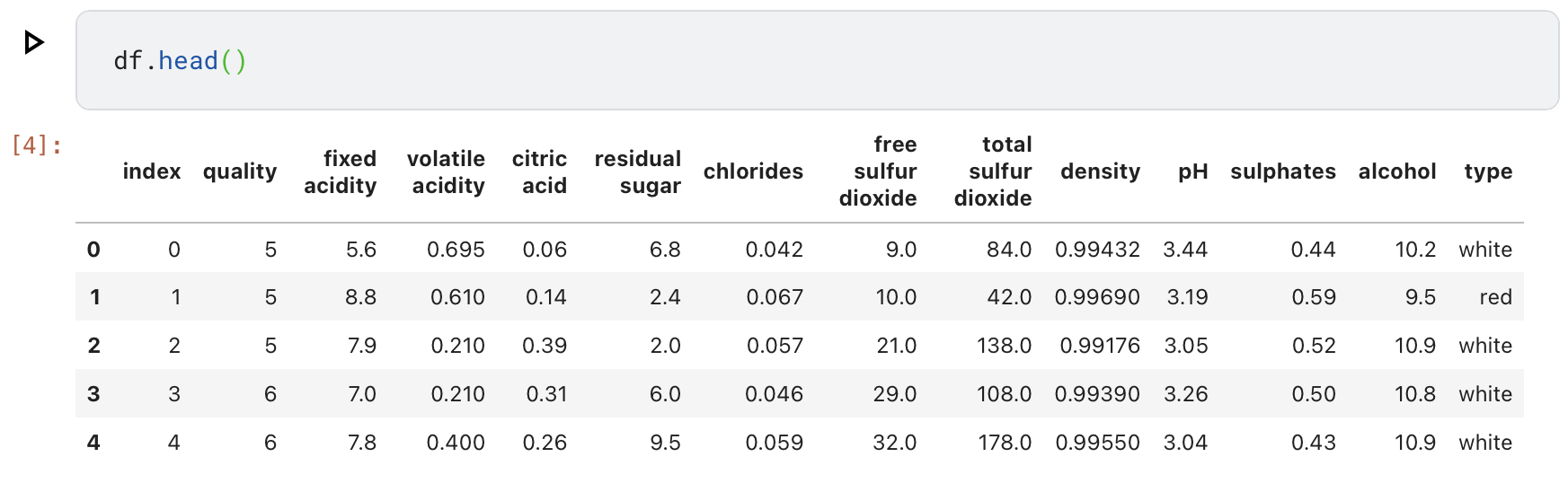
여기서 예측해야 하는 Y는 quality이며, 나머지는 feature로 사용해야 한다.

전체 컬럼의 null값은 없고, type만 object 타입인 것을 확인할 수 있다.
red, white 계열의 type만 존재하므로
df['type'] = df['type'].replace(['red', 'white'], [0, 1])인코딩을 진행했다.
여기선 생략됐지만, 각 컬럼별로 분포가 다르다.
scaling을 진행해야 한다.
그리고, 변수별로 상관관계를 파악해봤다.
corr = df.corr(method = 'pearson') sns.heatmap(data = corr, annot=True, fmt='.1f', cmap='Reds') plt.show()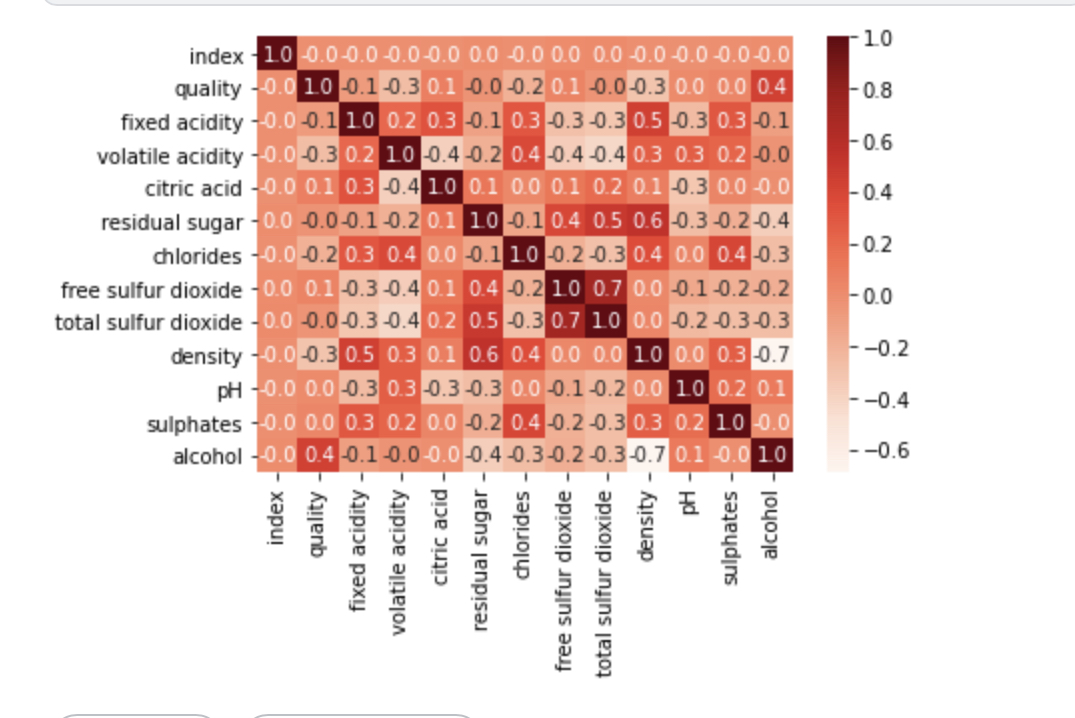
일반적으로 상관관계가 0.6~0.7이상이면 매우 상관관계가 높아 중요한 feature지만,
여기선 quality와 상관관계가 가장 높은 feature는 volatile acidity, density, alcohol로 선택하여
이 세 컬럼에 대해 이상치 데이터를 제거하기로 했다.
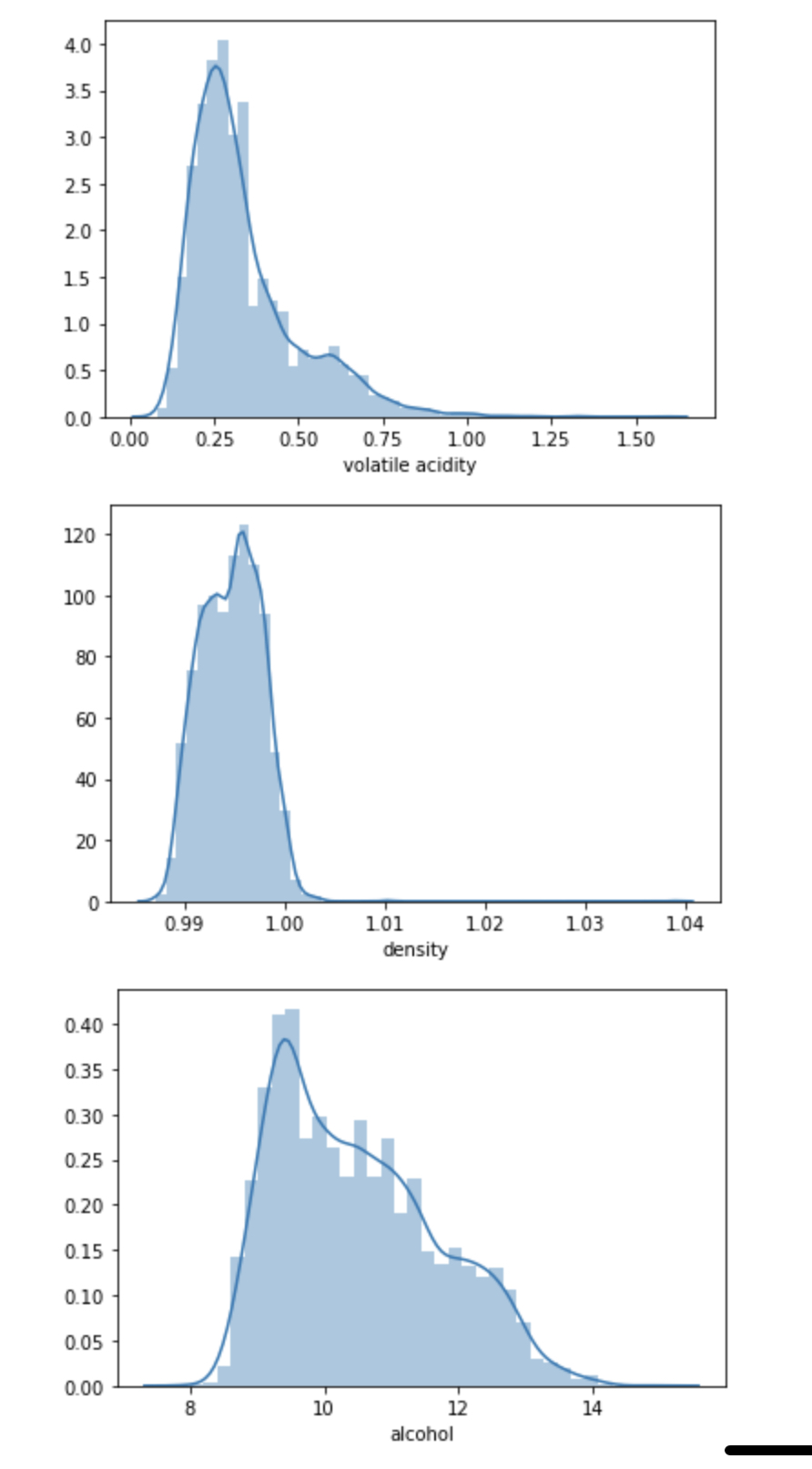
volatile acidity, density 같은 경우에는 이상치값들이 있는 것을 확인할 수 있는데,
지금 생각해보면 이상치값을 제거하면 안되는 요소인 것 같다.
이상치 탐지 혹은 binary classification 문제였다면,
이상치를 제거하여 변수를 만들지 말아야 한다고 생각한다.
하지만 이 데이터에서 이상치라고 하기에는 값의 범위가 크지 않고,
큰 영향을 주지 않을 것 같다.
이상치 제거
def check_outlier(df, col): IQR = df[col].quantile(0.75) - df[col].quantile(0.25) max_outlier = df[col].quantile(0.75) + 1.5*IQR min_outlier = df[col].quantile(0.25) - 1.5*IQR print(len(df[df[col] > max_outlier]), len(df[df[col] < min_outlier])) df = df.drop(df[df[col] > max_outlier].index, axis=0) df = df.drop(df[df[col] < min_outlier].index, axis=0) return df값의 범위가 달라 일반적인 standardscaler를 사용했다.
type과 quality를 제거하고 scaling을 진행했다.
sc = StandardScaler() Y = df['quality'] X = df.drop(columns=['quality']) X_scal = sc.fit_transform(X[X.columns[:-1]]) X_fin = np.column_stack((X_scal, X['type'].values)) Y = Y-3 ## pred시 +3해서 예측할것 X_train, X_test, y_train, y_test = train_test_split(X_fin, Y, test_size = 0.33, random_state = 12)여기서 Y(quality)값 3을 뺀 이유는 lgbm모델 param선언시,
num_classes 인자 때문이다.
params = { 'application' : 'multiclass', 'num_boost_round' : 1300, 'learning_rate' : 0.01, 'num_leaves' : 31, 'num_classes' : 7, 'metric' : 'multi_error' }현재 quality가 3~9 까지여서 y값의 개수는 총 7개가 나올 수 있다.
하지만 lgbm num_classes를 7로 선언시 자동으로 [0, 7)로 인식하기 때문에
predict한 결과에서 3을 더하는 방식으로 진행했다.
lgb_train = lgbm.Dataset(X_train, label = y_train) lgb_valid = lgbm.Dataset(X_test, label = y_test) evals_result = {} clf = lgbm.train(params, lgb_train, valid_sets=lgb_valid, evals_result=evals_result) lgbm.plot_metric(evals_result)[1] valid_0's multi_error: 0.555372
...
[1300] valid_0's multi_error: 0.369146
로 에러가 점점 줄어들고, loss graph를 살펴보면

더 이상 진행하면 overfitting이 발생할 수 있어 여기서 stop했다.
predict하고 나면 결과는
[ 0.1 0.3 .. 0.1 0.2] 이런식으로 나온다.
결과값이 가장 높은 값의 index를 가져와야 한다.
res_argmax = [np.argmax(n) for n in y_pred]그럼 테스트 데이터로 성능검증을 해보자.

빠르고, 간단하게 만들었는데 0.662가 나왔다.
이상치 데이터 제거하고 모델 학습도 해보고, 제거하지 않고도 학습해봤는데
데이터의 양이적어 큰 비중은 없는 것같다.
좀 더 결과적으로 분석해보자면
예측 결과의 quality가 4~8사이밖에 나오지 않았다.
나머지 0~3, 9에 대한 데이터를 늘려서 학습하거나,
scaling시 값이 너무 작아져 버려서 가중치가 작게 학습된거같다.
'ML&DL' 카테고리의 다른 글
ML Hyperparameter tuning (0) 2021.08.05 roc curve (0) 2021.05.06 bagging Emsemble, semi-supervised (2) 2021.03.11 [Data Cleansing] scaling과 normalization의 차이 (0) 2021.02.26 [Kaggle] santander product recomendation EDA (0) 2021.02.19