-
[Kaggle] santander product recomendation EDAML&DL 2021. 2. 19. 17:42
* Kaggle 우승작으로 배우는 머신러닝 탐구생활 정리
목표 : 고객별 신규 금융 상품 구매 찾기
캐글 santander-product-recomendation 데이터 사용
trn = pd.read_csv(''../input/santander-product-recomendation/train_ver2.csv') 사용
1. data length, dtypes 확인
trn.info
<class 'pandas.core.frame.DataFrame'> RangeIndex: 13647309 entries, 0 to 13647308 Data columns (total 48 columns): # Column Dtype --- ------ ----- 0 fecha_dato object 1 ncodpers int64 2 ind_empleado object 3 pais_residencia object 4 sexo object 5 age object 6 fecha_alta object 7 ind_nuevo float64 8 antiguedad object 9 indrel float64 10 ult_fec_cli_1t object 11 indrel_1mes object 12 tiprel_1mes object 13 indresi object 14 indext object 15 conyuemp object 16 canal_entrada object 17 indfall object 18 tipodom float64 19 cod_prov float64 20 nomprov object 21 ind_actividad_cliente float64 22 renta float64 23 segmento object 24 ind_ahor_fin_ult1 int64 25 ind_aval_fin_ult1 int64 26 ind_cco_fin_ult1 int64 27 ind_cder_fin_ult1 int64 28 ind_cno_fin_ult1 int64 29 ind_ctju_fin_ult1 int64 30 ind_ctma_fin_ult1 int64 31 ind_ctop_fin_ult1 int64 32 ind_ctpp_fin_ult1 int64 33 ind_deco_fin_ult1 int64 34 ind_deme_fin_ult1 int64 35 ind_dela_fin_ult1 int64 36 ind_ecue_fin_ult1 int64 37 ind_fond_fin_ult1 int64 38 ind_hip_fin_ult1 int64 39 ind_plan_fin_ult1 int64 40 ind_pres_fin_ult1 int64 41 ind_reca_fin_ult1 int64 42 ind_tjcr_fin_ult1 int64 43 ind_valo_fin_ult1 int64 44 ind_viv_fin_ult1 int64 45 ind_nomina_ult1 float64 46 ind_nom_pens_ult1 float64 47 ind_recibo_ult1 int64 dtypes: float64(8), int64(23), object(17) memory usage: 4.9+ GB--> data length는 13647309이고, numeric/categorical 변수가 합쳐져 있음
1-1. numeric한 컬럼의 값 범위 확인
num_cols = [col for col in trn.columns[:24] if trn[col].dtype in ['int64', 'float64']] trn[num_cols].describe() ncodpers ind_nuevo indrel tipodom cod_prov ind_actividad_cliente renta count 1.364731e+07 1.361958e+07 1.361958e+07 13619574.0 1.355372e+07 1.361958e+07 1.085293e+07 mean 8.349042e+05 5.956184e-02 1.178399e+00 1.0 2.657147e+01 4.578105e-01 1.342543e+05 std 4.315650e+05 2.366733e-01 4.177469e+00 0.0 1.278402e+01 4.982169e-01 2.306202e+05 min 1.588900e+04 0.000000e+00 1.000000e+00 1.0 1.000000e+00 0.000000e+00 1.202730e+03 25% 4.528130e+05 0.000000e+00 1.000000e+00 1.0 1.500000e+01 0.000000e+00 6.871098e+04 50% 9.318930e+05 0.000000e+00 1.000000e+00 1.0 2.800000e+01 0.000000e+00 1.018500e+05 75% 1.199286e+06 0.000000e+00 1.000000e+00 1.0 3.500000e+01 1.000000e+00 1.559560e+05 max 1.553689e+06 1.000000e+00 9.900000e+01 1.0 5.200000e+01 1.000000e+00 2.889440e+07--> tipodom 컬럼은 전체의 값이 1.0임 ( 학습에 도움이 되지 않는 컬럼으로 삭제 가능 )
--> 추후, 전처리를 할땐 ind_nuevo, tipodom_cod_prov, ind_actividad_cliente 같은 경우엔
int로 dtype을 변경하여 처리하면 데이터 용량 축소가 가능함
2-2. categorical한 컬럼의 값 요약
cat_cols = [col for col in trn.columns[:24] if trn[col].dtype in ['O']] trn[cat_cols].describe() fecha_dato ind_empleado pais_residencia sexo age fecha_alta antiguedad ult_fec_cli_1t indrel_1mes tiprel_1mes indresi indext conyuemp canal_entrada indfall nomprov segmento count 13647309 13619575 13619575 13619505 13647309 13619575 13647309 24793 13497528.0 13497528 13619575 13619575 1808 13461183 13619575 13553718 13457941 unique 17 5 118 2 235 6756 507 223 13.0 5 2 2 2 162 2 52 3 top 2016-05-28 N ES V 23 2014-07-28 0 2015-12-24 1.0 I S N N KHE N MADRID 02 - PARTICULARES freq 931453 13610977 13553710 7424252 542682 57389 134335 763 7277607.0 7304875 13553711 12974839 1791 4055270 13584813 4409600 7960220--> 컬럼의 개수가 13647309 count보다 작은경우에는 결측치가 있는 것으로 확인
ult_fec_cli_1t 같은 컬럼은 대부분이 결측치
--> ind_empleado 같은 경우, 'N' 값을 가진 row가 대략 90%이상을 차지하고 있으므로 데이터가 편향적
--> age, antiguedad(은행 누적거래 기간) 같은 경우 object로 분리되어 있어, 형변환 필요
2-2-1. categorical unique value 확인
for col in cat_cols: uniq = np.unique(trn[col].astype(str)) print('-'*50) print(f'# col {col}, n_uniq {len(uniq)}, uniq {uniq}') -------------------------------------------------- # col fecha_dato, n_uniq 17, uniq ['2015-01-28' '2015-02-28' '2015-03-28' '2015-04-28' '2015-05-28' '2015-06-28' '2015-07-28' '2015-08-28' '2015-09-28' '2015-10-28' '2015-11-28' '2015-12-28' '2016-01-28' '2016-02-28' '2016-03-28' '2016-04-28' '2016-05-28'] -------------------------------------------------- # col ind_empleado, n_uniq 6, uniq ['A' 'B' 'F' 'N' 'S' 'nan'] -------------------------------------------------- # col pais_residencia, n_uniq 119, uniq ['AD' 'AE' 'AL' 'AO' 'AR' 'AT' 'AU' 'BA' 'BE' 'BG' 'BM' 'BO' 'BR' 'BY' 'BZ' 'CA' 'CD' 'CF' 'CG' 'CH' 'CI' 'CL' 'CM' 'CN' 'CO' 'CR' 'CU' 'CZ' 'DE' 'DJ' 'DK' 'DO' 'DZ' 'EC' 'EE' 'EG' 'ES' 'ET' 'FI' 'FR' 'GA' 'GB' 'GE' 'GH' 'GI' 'GM' 'GN' 'GQ' 'GR' 'GT' 'GW' 'HK' 'HN' 'HR' 'HU' 'IE' 'IL' 'IN' 'IS' 'IT' 'JM' 'JP' 'KE' 'KH' 'KR' 'KW' 'KZ' 'LB' 'LT' 'LU' 'LV' 'LY' 'MA' 'MD' 'MK' 'ML' 'MM' 'MR' 'MT' 'MX' 'MZ' 'NG' 'NI' 'NL' 'NO' 'NZ' 'OM' 'PA' 'PE' 'PH' 'PK' 'PL' 'PR' 'PT' 'PY' 'QA' 'RO' 'RS' 'RU' 'SA' 'SE' 'SG' 'SK' 'SL' 'SN' 'SV' 'TG' 'TH' 'TN' 'TR' 'TW' 'UA' 'US' 'UY' 'VE' 'VN' 'ZA' 'ZW' 'nan'] -------------------------------------------------- # col sexo, n_uniq 3, uniq ['H' 'V' 'nan']--> fecha_dato 컬럼은 년-월-일 순이고, 매달 28일에 기록됨
--> ind_empleado, pais_residencia, sexo 는 nan값이 포함되어 있음
3. 데이터 시각화(count)
skip_cols = ['ncodpers', 'renta'] for col in trn.columns: # 출력에 너무 시간이 많이 걸리는 두 변수는 skip if col in skip_cols: continue # 보기 편하게 영역 구분 및 변수명 출력 print('='*50) print('col : ', col) # 그래프 크기 (figsize) 설정 f, ax = plt.subplots(figsize=(20, 15)) # seaborn을 사용한 막대그래프 생성 sns.countplot(x=col, data=trn, alpha=0.5) # show() 함수를 통해 시각화 plt.show()==================================================
col : fecha_dato

--> 2015-06-28 기준으로 데이터의 수가 많이 증가함을 알 수 있음
==================================================
col : ind_empleado

--> decribe()에서 확인한 내용처럼, 'N' 값의 개수가 매우 많은걸 확인할 수 있음
--> pais_residencia 컬럼도 비슷한 분포를 갖고 있음
==================================================
col : age
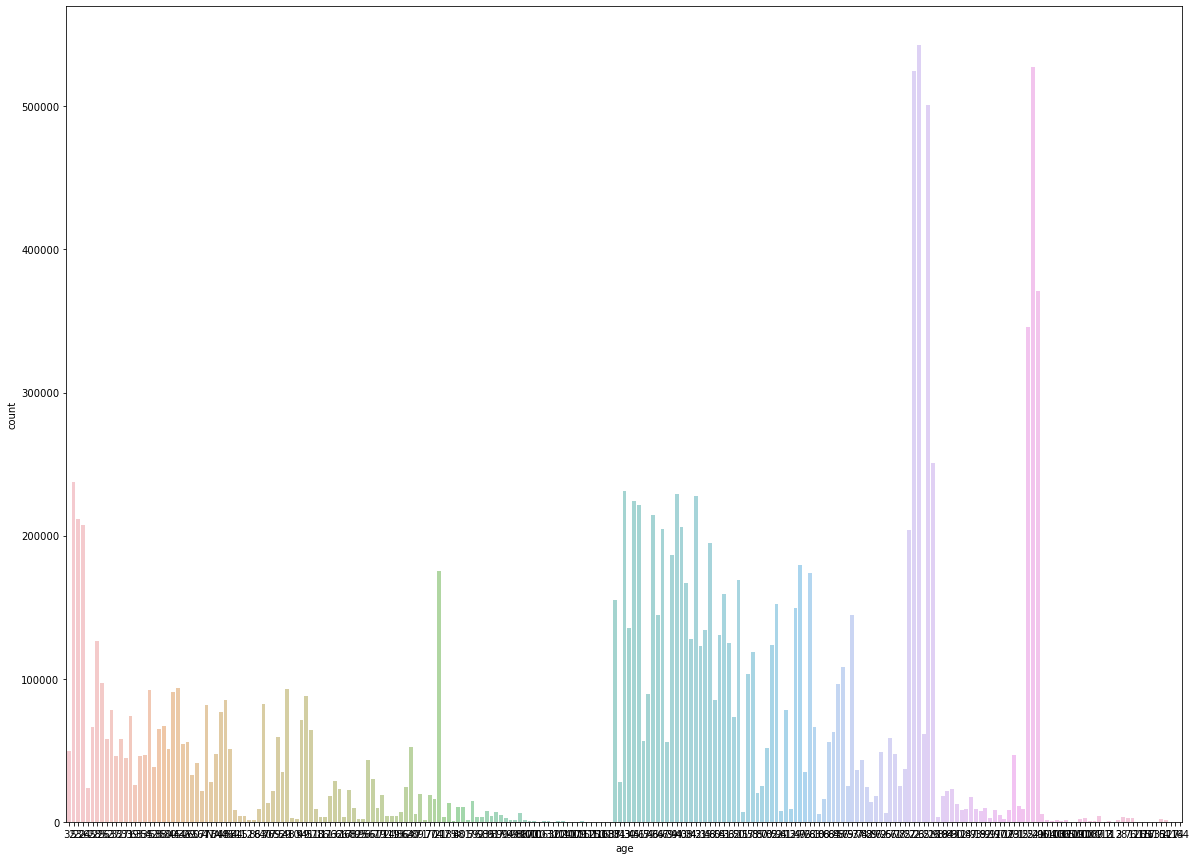
--> 중간에 끊긴 값들이 보임. type 문제일 가능성
int 로 변환하자 (antiguedad 도 비슷한 분포)
4. 시계열 데이터 시각화
이 데이터는 월별 고객의 금융제품 구매이력을 기록하고 있음
데이터 count 그래프는 시계열성을 고려하지 않았음
시계열 데이터를 옳바르게 분석하기 위해서는
시간에 따른 변화 척도를 눈에 볼 수 있도록 분석해야 함
예로 고객 유입 채널을 의미하는 canal_entrada 변수는
계절에 따라, 방학/입학 시즌에 따라 데이터의 분포가 변할 수 있으나,
앞선 기초 통계 및 시각화에서는 시계열성 변화를 포착하지 못했음
months = np.unique(trn['fecha_dato']).tolist() label_cols = trn.columns[24:].tolist() label_over_time = [] for i in range(len(label_cols)): label_sum = trn.groupby(['fecha_dato'])[label_cols[i]].agg('sum') label_over_time.append(label_sum.tolist()) label_sum_over_time = [] for i in range(len(label_cols)): label_sum_over_time.append(np.asarray(label_over_time[i:]).sum(axis=0)) color_list = ['#F5B7B1','#D2B4DE','#AED6F1','#A2D9CE','#ABEBC6','#F9E79F','#F5CBA7','#CCD1D1'] f, ax = plt.subplots(figsize=(30, 15)) for i in range(len(label_cols)): # 24개 금융 제품에 대하여 Histogram 그리기 sns.barplot(x=months, y=label_sum_over_time[i], color = color_list[i%8], alpha=0.7) plt.legend([plt.Rectangle((0,0),1,1,fc=color_list[i%8], edgecolor = 'none') for i in range(len(label_cols))], label_cols, loc=1, ncol = 2, prop={'size':16})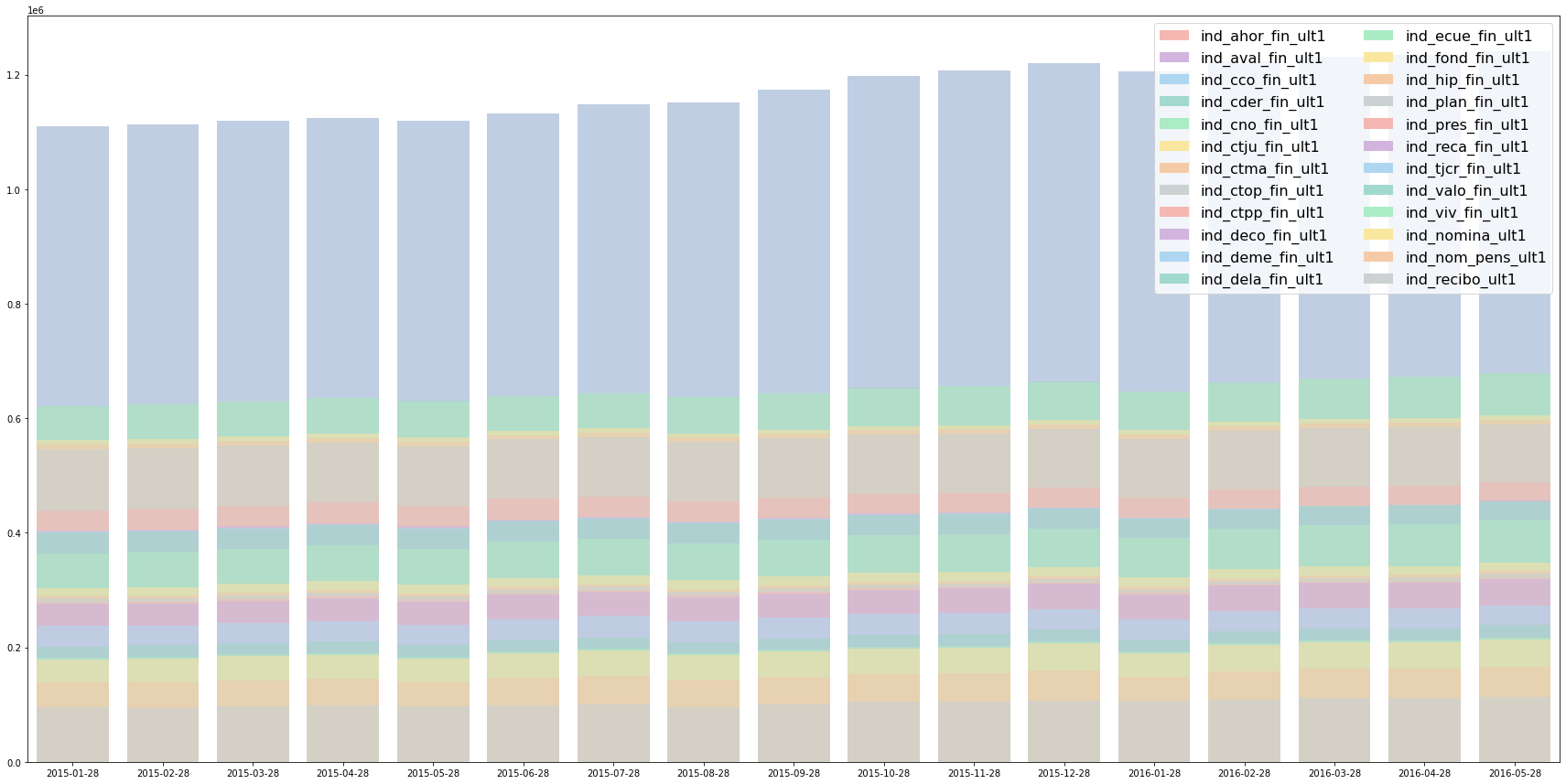
총 제품 보유 수량이 매달마다 조금씩 상승하고 있어,
고객의 숫자가 꾸준히 늘어나는 것에 영향이 있어보임
매번 달라지는 금융 제품 보유값에 무관하게 시각화를 하기 위해
절댓값이 아닌 상대값으로 시각화 해보기
label_sum_percent = (label_sum_over_time / (1.*np.asarray(label_sum_over_time).max(axis=0))) * 100 f, ax = plt.subplots(figsize=(30, 15)) for i in range(len(label_cols)): sns.barplot(x=months, y=label_sum_percent[i], color = color_list[i%8], alpha=0.7) plt.legend([plt.Rectangle((0,0),1,1,fc=color_list[i%8], edgecolor = 'none') for i in range(len(label_cols))], \ label_cols, loc=1, ncol = 2, prop={'size':16})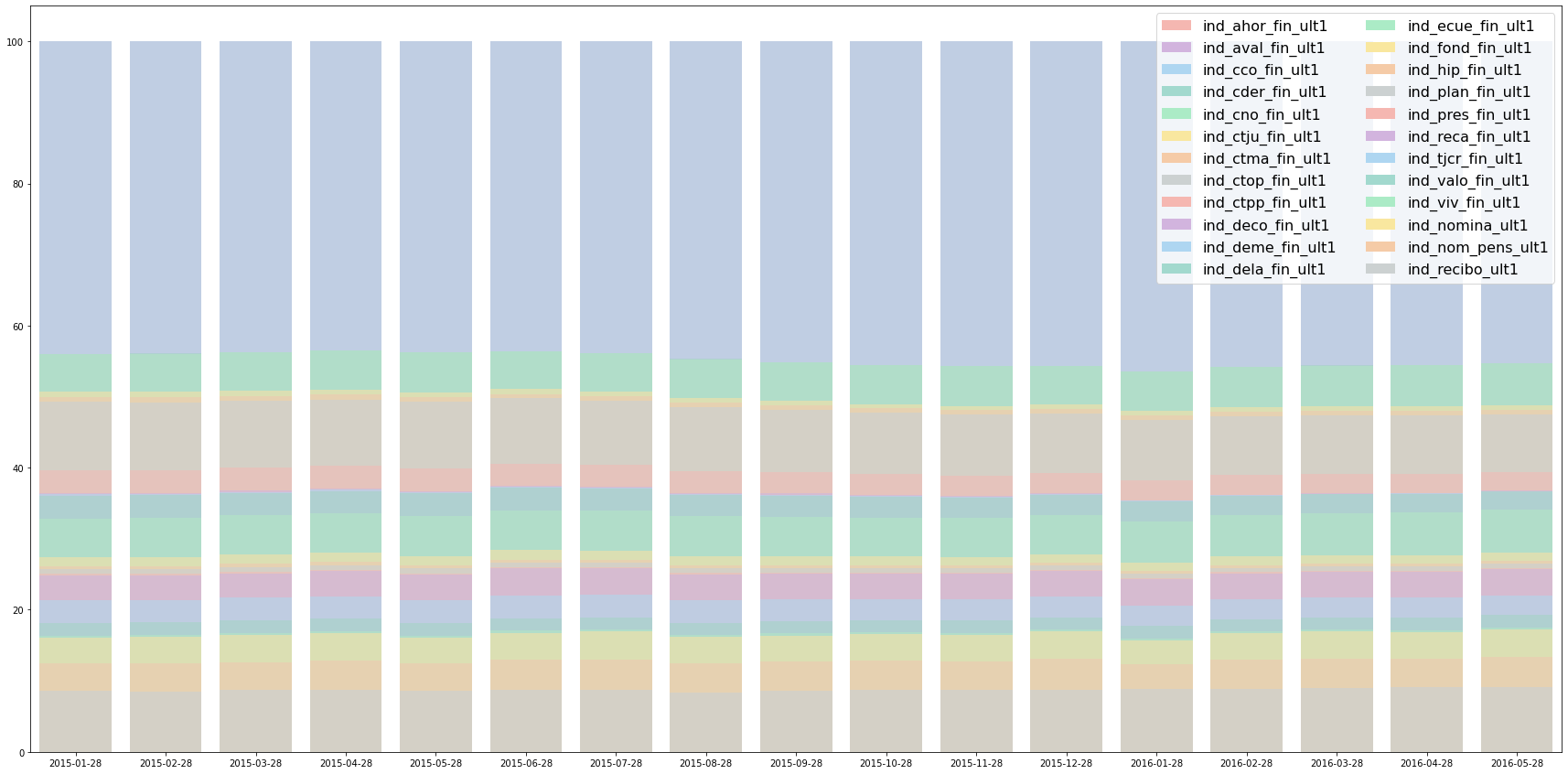
상대적으로 보았을 때도, 어떤 금융상품이 계절/시기적으로
더 많이 증가하는 변화/패턴등은 찾기 어려워 보임
이번 competition에서 예측해야하는 값은 고객이 신규로 구매할 제품
즉, 보유 여부가 0 -> 1로 변화는 시점에 대해 맞춰야 하는 것임
현재 count 막대 그래프는 제품의 총 보유량을 나타내고 있을 뿐,
우리가 원하는 신규 구매에 대한 월별 추이를 나타내지 않음
5. 문제/답에 맞는 데이터 변환
데이터는 단순히 월별 금융상품 보유에 대한 정보이므로
lag를 이용하여 한 달 전/후 데이터 만들어
신규 구매 여부를 판단할 수 있게끔 데이터를 변경해야 함
# labels prods = trn.columns[24:].tolist() def date_to_int(str_date): Y, M, D = [int(a) for a in str_date.strip().split("-")] int_date = (int(Y) - 2015)*12 + int(M) return int_date trn['int_date'] = trn['fecha_dato'].map(date_to_int).astype(np.int8) trn_lag = trn.copy() trn_lag['int_date'] += 1 trn_lag.columns = [col + '_prev' if col not in ['ncodpers', 'int_date'] else col for col in trn.columns] df_trn = trn.merge(trn_lag, on =['ncodpers', 'int_date'], how ='left') del trn, trn_lag # 저번달의 제품정보가 결측치 인 경우 for prod in prods: prev = prod + '_prev' df_trn[prev].fillna(0, inplace = True) # padd 변수를 통해 신규 구매 변수를 구함 for prod in prods: padd = prod + '_add' prev = prod + '_prev' df_trn[padd] = ((df_trn[prod] == 1) & (df_trn[prev] == 0)).astype(np.int8) add_cols = [prod + '_add' for prod in prods] labels = df_trn[add_cols].copy() labels.columns = prodslabels.head() ind_ahor_fin_ult1 ind_aval_fin_ult1 ind_cco_fin_ult1 ind_cder_fin_ult1 ind_cno_fin_ult1 ind_ctju_fin_ult1 ind_ctma_fin_ult1 ind_ctop_fin_ult1 ind_ctpp_fin_ult1 ind_deco_fin_ult1 ... ind_hip_fin_ult1 ind_plan_fin_ult1 ind_pres_fin_ult1 ind_reca_fin_ult1 ind_tjcr_fin_ult1 ind_valo_fin_ult1 ind_viv_fin_ult1 ind_nomina_ult1 ind_nom_pens_ult1 ind_recibo_ult1 0 0 0 1 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 2 0 0 1 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 1 ... 0 0 0 0 0 0 0 0 0 0 4 0 0 1 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 5 rows × 24 columns--> 라벨값 생성
6-1. 월별 신규 구매 데이터 시각화
fecha_dato = trn['fecha_dato'] labels['date'] = fecha_dato months = np.unique(fecha_dato).tolist() label_cols = labels.columns.tolist()[:24] label_over_time = [] for i in range(len(label_cols)): label_over_time.append(labels.groupby(['date'])[label_cols[i]].agg('sum').tolist()) label_sum_over_time = [] for i in range(len(label_cols)): label_sum_over_time.append(np.asarray(label_over_time[i:]).sum(axis=0)) color_list = ['#F5B7B1','#D2B4DE','#AED6F1','#A2D9CE','#ABEBC6','#F9E79F','#F5CBA7','#CCD1D1'] f, ax = plt.subplots(figsize=(30, 15)) for i in range(len(label_cols)): sns.barplot(x=months, y=label_sum_over_time[i], color = color_list[i%8], alpha=0.7) plt.legend([plt.Rectangle((0,0),1,1,fc=color_list[i%8], edgecolor = 'none') for i in range(len(label_cols))], label_cols, loc=1, ncol = 2, prop={'size':16})
--> 첫 달인 2015-05-28은 데이터의 첫달에는 모든 보유제품이 신규 구매로 인식됨
상대값 기준으로 시각화
6-2. 월별 신규 구매 상대값 기준 시각화
label_sum_percent = (label_sum_over_time / (1.*np.asarray(label_sum_over_time).max(axis=0))) * 100 f, ax = plt.subplots(figsize=(30, 15)) for i in range(len(label_cols)): sns.barplot(x=months, y=label_sum_percent[i], color = color_list[i%8], alpha=0.7) plt.legend([plt.Rectangle((0,0),1,1,fc=color_list[i%8], edgecolor = 'none') for i in range(len(label_cols))], \ label_cols, loc=1, ncol = 2, prop={'size':16})
--> 당좌 예금(ind_cco_fin_ult1, 위에서 첫번째 영역) : 8월 여름에 가장 높은 값을 가지며, 겨울에는 축소되는 계절 추이
--> 단기 예금(ind_deco_fin_ult1, 위에서 다섯번째 그래프에서 가운데 파란 영역) : 이 시기에만 높은 값을 가지며, 다른 시기에는 값이 매우 낮음
--> 급여, 연금(ind_nomina_ult1, ind_nom_pens_ult1) : 당좌 예금과 반대로 8월 여름에 가장 낮은 값을 가지며 2016-02-28 겨울에 가장 높은 값을 가지는 추세
--> 신규구매빈도가 가장 높은 5개 금융 제품은 당좌 예금, 신용 카드, 급여, 연금 그리고 직불카드
(ind_cco_fin_ult1, ind_tjcr_fin_ult1, ind_nomina_ult1, ind_nom_pens_ult1, ind_recibo_fin_ult1)
7. 결론
데이터가 계절성을 뛴다는 것은, 훈련 데이터를 몇월로 지정하는가에 따라
머신러닝의 결과물이 많이 달라질 수 있음
계절의 변동성을 모델링하는 하나의 일반적인 모델을 구축할 것인지,
계절에 따라 다수의 모델을 구축하여 혼합해서 사용할지를 결정해야 함
하나의 일반적인 모델을 구축할 것인지, 계절에 따라 다수의 모델을 구축하여 혼합해서 사용할지를 결정해야 함
8. 데이터 전처리시 유의사항
--> 'age', 'antiguedad', 'indrel_1mes' 등의 수치 변수가 object로 표현되어 데이터 정제작업이 필요함
--> 대부분의 고객 변수에 결측값이 존재함
--> 0, 1밖에 없는 컬럼이지만 float타입인 경우, type casting이 필요함
'ML&DL' 카테고리의 다른 글
[dacon] 와인품질 EDA 및 1차 모델 개발 (0) 2021.06.14 roc curve (0) 2021.05.06 bagging Emsemble, semi-supervised (2) 2021.03.11 [Data Cleansing] scaling과 normalization의 차이 (0) 2021.02.26 데이터 분석시 해야 할 작업 (0) 2020.04.20